Do not index
안녕하세요. 오토피디아의 서비스개발팀장을 맡고 있는 김승수입니다. 오토피디아 서비스개발팀에서는 기존 EC2 기반 인프라를 ECS를 이용한 컨테이너 기반 인프라로 전환을 진행하였습니다. 그 과정에서 ECS에서 새로 등장하는 개념들이 아주 많았는데요, AWS 문서는 중요한 개념과 중요하지 않은 개념들에 대한 설명이 섞여 있어 이해에 어려움을 겪었습니다. 따라서, ECS의 많은 개념들을 확실히 정리하여, ECS 기반 인프라를 구축하시려는 분들께 좋은 레퍼런스가 되었으면하는 마음으로 이 글을 작성합니다.
1. ECS로의 전환 이유기존 인프라 구성기존 인프라의 문제점ECS의 장점2. ECS 기본 개념클러스터(Cluster)용량 공급자(Capacity Provider)와 용량 공급자 전략 (Capacity Provider Strategy)용량 공급자용량 공급자 전략작업 정의(Task Definition)와 작업(Task)네트워크 모드환경 변수작업 역할(Task Role)과 작업 실행 역할(Task Execution Role)서비스(Service)ECR 이미지 저장소(ECR Repository)3. ECS로 서비스 출시하기ECS 클러스터 생성ECS 클러스터 생성오토스케일링 그룹 생성오토스케일링 그룹을 ECS 클러스터 용량공급자로 등록컨테이너별 Dockerfile 작성ECR 이미지 저장소 생성taskdef.json 작성작업 IAM 역할 및 작업 실행 IAM 역할 생성ECS 작업 정의 및 서비스 생성작업 정의 생성서비스 생성 (서비스 기본 설정)서비스 생성 (로드밸런서 설정)서비스 생성 (오토스케일링 설정)서비스 생성 완료4. 소소한 팁ECS 모범 사례블루/그린 배포 시 클러스터 여유 리소스 확보CI/CD 파이프라인복수의 컨테이너 관리5. 마치며 — 다음엔 같이해요
1. ECS로의 전환 이유
본격적인 글을 시작하기에 앞서, ECS로의 인프라 전환을 선택하게된 이유에 대해서 말씀 드리려고 합니다. 이미 컨테이너 기반 인프라의 장점에 대해 잘 아시는 분들은 다음 장으로 넘어가셔도 괜찮습니다.
기존 인프라 구성
오토피디아에서는 운전자 분들의 차량 문제를 해결해 드리는 닥터차 서비스를 운영중인데요, 이 닥터차 서비스 API 서버를 위한 인프라를 Terraform으로 관리하고 있었습니다. 닥터차 모놀리틱 API 서버는 EC2 오토스케일링 그룹에 속한 EC2 인스턴스들에 CodePipeline을 통해 배포되고 있었습니다.
기존 인프라의 문제점
이러한 상황에서 타이어 노면 사진을 통해 타이어 홈의 남은 깊이를 측정하고, 교체가 필요한 경우 타이어를 구매할 수 있는 타이어 커머스 서비스를 추가하려고 하였습니다. 그 과정에서,
- 새로운 타이어 커머스 API 서버를 위한 서버 환경을 다시 구성해야했고,
- MVP인 타이어 커머스 API 서버의 자원 사용량이 크지 않음에도 인스턴스 하나를 통째로 사용해야했으며,
- Terraform으로는 EC2 오토스케일링 그룹에 대한 CodeDeploy 블루/그린 배포 방식을 관리할 수 없다
는 문제에 부딪혔습니다.
저희는 이 문제들이 빠른 시일 내에 다시 반복될 것이라고 생각했습니다. 그 이유는 크게 두가지였습니다. 첫번째로, 타이어 커머스 외에도 신규 MVP 서비스들을 런칭해야할 상황이 올 것이라고 생각했습니다.
두번째로, 타이어 커머스는 기존 닥터차 서비스의 결제, 차종 기능 등을 활용해야했는데요, 그러면 타이어 커머스 API 서버로부터 모놀리틱 닥터차 API 서버로의 의존성이 발생하는 문제가 발생했습니다. 이를 해결하기 위해서는 결제, 차종, 인증 등 이후 신규 서비스들에서 공통적으로 사용하게 될 기능들을 마이크로서비스 형태로 분리해야한다는 결론을 내렸습니다. 이러한 마이크로서비스들을 런칭할 때도 신규 서비스 런칭 시와 동일한 문제가 발생할 것이라고 생각했습니다.
ECS의 장점
따라서, 저희는 ECS를 활용한 컨테이너 기반 인프라로의 전환을 결정하게 되었습니다.
- 공개된 이미지들에 몇가지 설정만을 더하는 방식으로 쉽게 환경을 구성할 수 있고,
- 0.25vCPU, 256MB 메모리 등, 작은 단위로 자원을 분배할 수 있며,
- Terraform으로 ECS에 대한 CodeDeploy 블루/그린 배포 방식을 관리할 수 있기 때문에
기존의 문제를 모두 해결할 수 있습니다.
2. ECS 기본 개념
ECS에는 EC2에는 없었던 여러 개념들이 새로 등장합니다. 이 개념들에 대해 잘 이해하고 있어야 서비스를 올바르게 운영할 수 있습니다. 본격적인 개념 소개 전에, 이 글에서 등장할 개념들의 관계에 관한 도식을 먼저 보여 드립니다. 글을 읽으시다가 이해가 되지 않는 부분이 있다면 이 도식을 참고하시기 바랍니다.
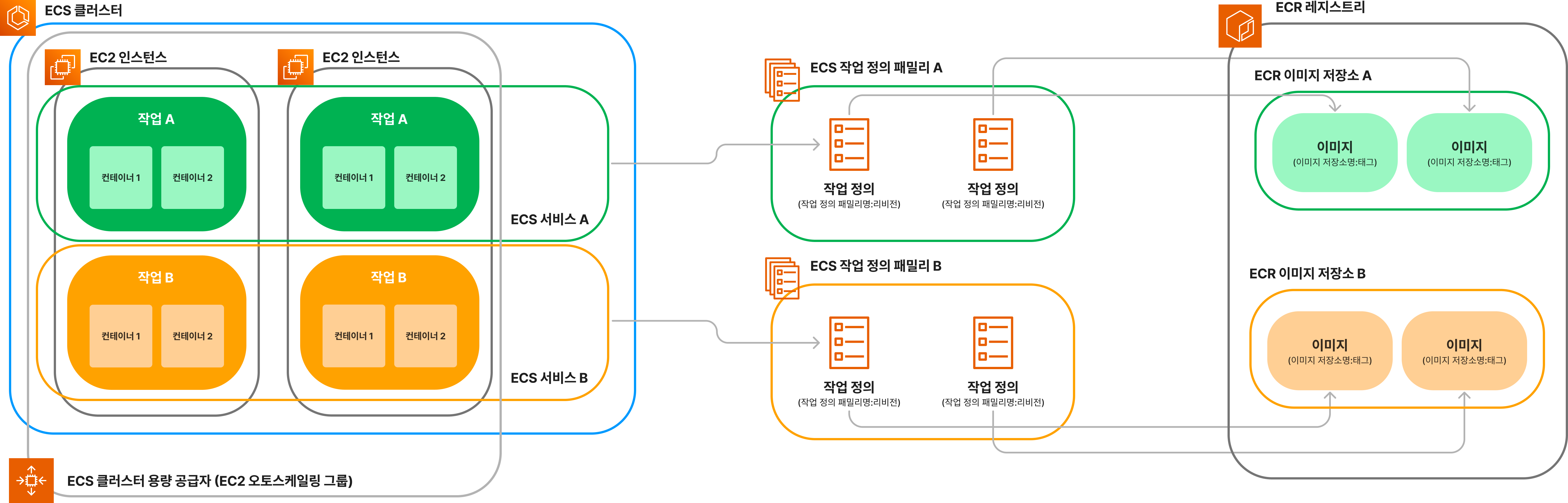
또한, 글에 연관된 AWS 문서를 링크로 걸어 두었으니, 더 자세한 설명이 필요하신 분들은 AWS 문서를 참고하시기 바랍니다.
클러스터(Cluster)
클러스터의 정확한 정의는 작업 또는 서비스의 논리적 그룹이라고 AWS 문서에 서술되어 있으나, 컨테이너들을 실행시키기 위해한 CPU, 메모리 등의 자원(용량)의 묶음이라고 이해하시면 편합니다. 클러스터의 자원을 공급하는 방식(시작 유형)에는 EC2 인스턴스, 외부 인스턴스, 그리고 Fargate가 있습니다. EC2 인스턴스와 외부 인스턴스 유형은 인스턴스에 ECS agent를 설치해 물리적 자원인 인스턴스를 클러스터에 등록하는 유형입니다. Fargate 유형은 별도의 물리적인 인스턴스 없이, AWS가 관리하는 자원 풀을 사용하는 유형입니다. 물리적 자원인 인스턴스를 관리할 필요가 없다는 장점이 있으나, 컨테이너가 실행되는 인스턴스에 직접 접근할 수 없으므로 디버깅 시에 복잡하다는 단점과, 비용이 다른 유형에 비해 비싸다는 단점이 있습니다. 저희는 EC2 인스턴스 시작 유형을 사용했기에 이를 기준으로 설명을 이어가도록 하겠습니다.
용량 공급자(Capacity Provider)와 용량 공급자 전략 (Capacity Provider Strategy)
용량 공급자
용량 공급자는 클러스터에 용량(자원)을 공급하는 방법입니다. EC2 인스턴스 시작 유형의 클러스터의 경우 EC2 오토스케일링 그룹이 유일한 용량 공급자 종류입니다. 빈 EC2 오토스케일링 그룹을 생성해 클러스터의 용량 공급자로 등록하면, ECS가 필요에 따라 EC2 오토스케일링 그룹의 크기를 조정합니다. 더 자세하게는, 용량 공급자로 등록된 EC2 오토스케일링 그룹마다
CapacityProviderReservation 값에 대한 CloudWatch 알람을 생성합니다. 이 값이 100을 초과하면 EC2 오토스케일링 그룹의 크기를 증가시키고, 100 미만이라면 크기를 감소 시킵니다. CapacityProviderReservation 값은 클러스터에서 실행되어야하는 작업 개수에 따라서 자동으로 조정됩니다. 클러스터 오토스케일링 작동 방식에 대한 더 자세한 설명은 AWS 문서를 참고하세요.용량 공급자 전략
하나의 클러스터에 여러 용량 공급자가 등록된 경우, 용량 공급자 전략에 따라 작업이 실행될 용량 공급자가 결정됩니다. 용량 공급자 전략은 하나 이상의 용량 공급자로 구성되며, 각 용량 공급자마다 기준(
base)과 가중치(weight) 값을 설정할 수 있습니다. 기준 값은 해당 용량 공급자에 최소한으로 실행되어야할 작업의 개수를 의미합니다. 기준 값은 하나의 용량 공급자 전략에 포함된 여러 용량 공급자 중 하나의 용량 공급자에 대해서만 설정될 수 있습니다. 가중치 값은 기준 값을 초과한 개수의 작업을 실행 시, 초과된 작업들이 여러 용량 공급자에 배분되는 비율을 결정합니다.설명이 상당히 복잡한데요, 예시를 보면 훨씬 이해하기 쉽습니다. 예를 들어, 한 클러스터에 A와 B, 두 용량 공급자가 등록된 경우를 생각해 봅시다. 용량 공급자 A에 대해 1의 기준 값과 1의 가중치 값, 용량 공급자 B에 대해 2의 가중치 값이 설정된 용량 공급자 전략을 통해 작업을 실행하는 경우, 첫 1개의 작업은 A에서 실행되고, 이후 작업들에 대해서는 1:2의 비율로 A와 B에서 실행되게 됩니다.
클러스터의 기본 용량 공급자 전략을 설정할 수 있습니다. 이후 작업 정의로부터 바로 작업을 실행하거나, 서비스를 통해 작업을 실행하는 경우, 클러스터의 기본 용량 공급자 전략을 사용하거나, 새로운 용량 공급자 전략을 설정해 사용할 수 있습니다.
이 글에서는 클러스터에 하나의 용량 공급자만 등록할 예정입니다. 용량 공급자 전략은 하나의 클러스터에 여러 용량 공급자가 등록된 경우에만 의미가 있으므로, 이 글을 따라가기 위해 용량 공급자 전략에 대해 완벽히 이해하지 않아도 됩니다.
작업 정의(Task Definition)와 작업(Task)
작업 정의는 작업에서 실행될 하나 이상의 컨테이너에 대한 JSON 형식의 환경 설정입니다. 컨테이너별로는 할당될 CPU/메모리 크기, 포트 매핑 목록, 환경 변수 목록, 연결할 볼륨 목록 등이 포함되며, 작업 별로는 네트워크 모드, 작업에 할당될 IAM role ARN, 작업을 실행시키는데 사용할 IAM role ARN 등이 포함됩니다. ECS 모범 사례에서는 별도 프로세스로 실행되어야 한다면 한 작업 내 별도의 컨테이너를 사용하라고 권장하고 있습니다. 예를 들어, 웹 애플리케이션을 실행하기 위한 작업을 구성하기 위해 하나의 작업 정의에 nginx 컨테이너와 애플리케이션 컨테이너를 포함할 수 있습니다.
작업 정의는 한번 생성되면 삭제할 수 없습니다. 작업 정의를 수정하려면, 기존의 작업 정의로부터 수정된 새로운 작업 정의를 생성해야합니다. 이러한 작업 정의의 버전들을 구분하기 위해 작업 정의에는 리비전이라는 자동으로 증가되는 숫자 값이 할당됩니다. 서로 다른 리비전을 갖는 작업 정의의 모음을 작업 정의 패밀리라고 부릅니다. 예를 들어,
drcha 작업 정의 패밀리에 drcha:1, drcha:2 등의 작업 정의들이 포함될 수 있습니다.여러개의 작업이 하나의 작업 정의로부터 실행될 수 있습니다. 작업 정의로부터 곧바로 하나의 작업을 생성할 수도 있고, 서비스를 통해 작업 정의로부터 여러개의 작업을 생성하고 관리할 수 있습니다. 향후 설명하겠지만, 서비스를 통해 작업을 실행하는 것이 오토스케일링, 로드밸런서 연결 등 추가 기능을 제공하므로 작업 정의로부터 곧바로 작업을 실행하는 것보다 좋습니다.
네트워크 모드
작업 정의의 여러 설정 중 중요한 설정 몇가지가 있습니다. 첫번째는 네트워크 모드입니다. 네트워크 모드에는
awsvpc, bridge, host, none이 있습니다. 그 중 awsvpc 모드는 각 작업마다 별개의 네트워크 인터페이스를 할당하는 방식입니다. 따라서, 각 작업이 프라이빗 IP 주소를 할당 받게 되고 따라서 작업이 어느 EC2 인스턴스에서 실행되는지와 별개로 보안 그룹을 적용할 수 있습니다. 이러한 장점이 있기 때문에 AWS는 별다른 이유가 없는 한 awsvpc 네트워크 모드를 사용할 것을 권장합니다.awsvpc 네트워크 모드 사용 시, 작업마다 네트워크 인터페이스를 할당하게됩니다. 그러나, EC2 인스턴스 유형별로 할당 가능한 네트워크 인터페이스의 개수에는 한계가 있습니다. 따라서, 인스턴스의 CPU, 메모리 자원은 충분하지만, 할당 가능한 네트워크 인터페이스 개수가 부족해 인스턴스에 새로운 작업을 실행하지 못할 수 있습니다.
이를 해결하기 위해 네트워크 인터페이스 truncking을 활용할 수 있습니다. 이를 활용하면 하나의 인스턴스에 할당할 수 있는 네트워크 인터페이스 개수가 늘어납니다. (물리적인 네트워크 인터페이스 개수는 아닙니다.) 그러나, 적용할 수 있는 인스턴스 유형이 제한되어 있습니다.환경 변수
작업에 포함된 각 컨테이너에 환경 변수를 설정하는 방식은 크게 세가지가 있습니다.
environment field를 통해 환경 변수 이름과 값을 직접 설정하거나, environmentFiles field를 통해 환경 변수들이 포함된 S3 object로부터 환경 변수를 가져오거나, secrets field를 통해 AWS Secrets Manager 서비스의 secret 값, 또는 AWS System Manager 서비스의 Parameter Store 파라미터를 가져오는 방법입니다. API key와 같은 민감 정보들은 반드시 secrets field를 통해 전달해야 민감 정보의 노출을 막을 수 있습니다.이 글에서 다룰 범위는 아니지만, CI/CD 파이프라인을 구축할 경우
taskdef.json 파일을 프로젝트에 포함 시키고, 파이프라인 실행 과정에서 taskdef.json 파일로부터 새로운 작업 정의를 생성하고 생성한 작업 정의에 기반한 작업을 배포하게 됩니다. 이 말인즉슨, 애플리케이션 코드 뿐만 아니라 cpu와 메모리 할당량, 환경 변수 등, 작업 정의 파라미터들도 코드를 통해 고치고 배포하여 변경할 수 있다는 뜻입니다. 따라서 애플리케이션 코드가 수정됨에 따라 같이 수정되어야하거나, 잦은 수정이 발생하는 환경 변수의 경우 environmentFiles보다는 environment field를 사용해 하드코딩하는 것이 좋습니다.오토피디아에서는 Terraform을 통해 인프라를 관리하고 있습니다. 따라서 DB 클러스터 엔드포인트, SQS queue 엔드포인트 등, Terraform을 통해 관리되는 인프라에 대한 정보를 환경 변수로 주입해야하는 경우 해당 환경 변수들을 포함하는 S3 object를 Terraform으로 관리하고 이 S3 object 내용을
environmentFiles field를 통해 환경 변수로 주입합니다.작업 역할(Task Role)과 작업 실행 역할(Task Execution Role)
작업 정의에는 두개의 IAM 역할 ARN을 등록해야합니다. 두 역할의 이름이 비슷하기 때문에 헷갈리기 쉽습니다.
먼저 작업 역할은 작업 정의로부터 실행될 작업들에 부여될 IAM 역할입니다. 예를 들어, 작업에 포함된 애플리케이션이 SQS queue로부터 메세지를 받아와야한다면, 해당 queue에 대한
sqs:ReceiveMessage 권한이 필요합니다. 이때, 작업 역할에 해당 권한을 포함하는 정책을 연결하고 애플리케이션에서 aws-sdk를 통해 queue에서 메세지 수신 요청을 보내면 aws-sdk는 실행되는 작업에 연결된 역할을 위임 받기 때문에 메세지 수신 요청이 성공합니다.작업 실행 역할은 작업 정의로부터 작업을 실행하는 과정에서 사용될 IAM 역할입니다. 작업을 실행하는 과정에는 ECR 저장소에서 이미지를 가져오거나, 환경 변수를 포함한 S3 객체를 읽어오거나, AWS Secrets Manager에 저장된 secret들의 값을 읽어와야 할 수 있습니다. 이러한 권한들을 포함한 정책을 작업 실행 역할에 연결하면 됩니다. 더 자세한 작업 실행 역할 설정 방법은 이 글 후반에 설명하도록 하겠습니다.
서비스(Service)
서비스를 사용하면 작업 정의로부터 원하는 수의 작업을 실행할 수 있습니다. 또한, 작업이 알 수 없는 이유로 실패하거나 중지된 경우, 실패하거나 중지된 작업을 삭제하고, 새로운 작업을 실행시켜 작업 개수를 맞춥니다. 더하여 오토스케일링, 로드밸런서, 작업 배치 전략, CodeDeploy 등 추가 기능을 설정할 수도 있습니다. 따라서, 작업 정의로부터 작업을 바로 실행하기보다는, 서비스를 통해 작업을 실행하는 것이 좋습니다.
ECR 이미지 저장소(ECR Repository)
빌드된 컨테이너 이미지를 저장할 도커 허브와 같은 저장소가 필요합니다. AWS는 이를 위해 계정 별로 Elastic Container Registry(ECR)를 제공하고, 레지스트리에 여러개의 공개 또는 프라이빗 저장소를 생성할 수 있게합니다. 이미지 저장소에 접근하기 위해서는 저장소가 포함된 레지스트리에 대한 인증 과정을 거쳐야합니다. 자세한 내용은 이 글 후반에 설명하도록 하겠습니다.
3. ECS로 서비스 출시하기
ECS의 기본 개념들에 대해 이해했으니, 간단한 서비스를 ECS를 통해 운영 해봅시다. 이를 위해서 ECS 클러스터, 작업 정의 서비스, ECR 이미지 저장소, 오토스케일링 그룹, 로드 밸런서와 타겟 그룹, IAM 역할 및 정책, 보안 그룹 등 많은 AWS 리소스들을 생성합니다. 콘솔을 통해 모든 리소스들을 생성할 수 있고, 이 글도 콘솔 사용을 가정하고 작성하겠으나, 운영 환경 구성 시에는 Terraform과 같은 IaaC 서비스를 사용할 것을 강력히 권장합니다. 콘솔로 많은 리소스를 생성 시 실수할 확률이 높고, 이로 인해 최종 인프라 구성에 실패 할 경우 실수를 찾아내기도 매우 힘듭니다.
ECS 클러스터 생성
먼저 ECS 클러스터를 생성하고 EC2 오토스케일링 그룹을 생성한 클러스터의 용량공급자로 등록합니다. 이미 사용중인 ECS 클러스터가 있는 분들은 다음 단계로 넘어가셔도 좋습니다.
ECS 클러스터 생성
ECS 콘솔에서 “클러스터 생성(Create Cluster)” 버튼을 통해 새로운 클러스터를 생성합니다.
오토스케일링 그룹 생성
EC2 콘솔의 시작 템플릿(Launch Template) 메뉴에서 새로운 시작 템플릿을 생성합니다. 이 시작 템플릿은 ECS 클러스터의 용량공급자로 사용될 오토스케일링 그룹 인스턴스들에 적용됩니다.
AMI는 ECS 최적화 AMI 중 하나를 선택합니다. ECS 최적화 AMI들은 별도의 설치 없이도 기본으로 ECS agent를 포함하고 있습니다. AWS에서 제공하는 Amazon Linux ECS 최적화 AMI 목록은 AWS 문서에서 확인 가능합니다. 또는 원하는 OS에 ECS agent를 설치하여 직접 AMI를 생성하고 사용해도 됩니다.
ECS agent는 agent가 실행 중인 인스턴스를 ECS 클러스터에 등록하고, 클러스터에서 실행해야할 작업들을 해당 인스턴스에 실행시키는 역할을 합니다. 이를 위해서는 ECS agent가 연결될 클러스터명을 입력해주어야합니다. 고급 설정(Advanced details)의 User Data field를 다음과 같이 설정하여 ECS agent가 연결될 클러스터명을 설정합니다. 연결될 클러스터명 이외에 다른 설정값을 변경하기 위해서는 AWS ECS 컨테이너 에이전트 구성 문서를 참조합니다.
#!bin/bash
echo Configuring ECS agent...
sudo cat > /etc/ecs/ecs.config <<EOF
ECS_CLUSTER=[ECS 클러스터명]
EOF인스턴스들에 적용될 보안 그룹을 생성하고 시작 템플릿에 지정합니다. 인스턴스에서 실행되는 ECS agent는 Amazon ECS 서비스 엔드포인트와 통신하기 위해 외부 네트워크에 액세스해야 합니다. 따라서 외부 네트워크로의 outbound 연결을 허용하는 규칙을 반드시 포함합니다. 인스턴스에서 실행될 작업들을 위한 보안 그룹 규칙은 지금 설정하지 않습니다.
awsvpc 네트워크 모드 사용 시, 각 작업마다 네트워크 인터페이스가 생성되어 연결되므로 각 작업에는 작업이 실행되는 인스턴스의 네트워크 인터페이스에 적용된 보안 그룹이 적용되지 않습니다. 따라서 이후 작업마다 사용할 보안 그룹을 별도로 생성하고, 해당 보안 그룹에 규칙을 설정합니다. awsvpc 네트워크 모드를 사용하지 않는 경우 작업은 작업이 실행되는 인스턴스의 네트워크 인터페이스르 사용하므로, 인스턴스의 보안 그룹에 규칙을 설정해야합니다. 그러나 어떤 작업이 어떤 인스턴스에서 실행 될지 알 수 없으므로, 클러스터에서 실행할 모든 작업에 필요한 규칙을 인스턴스 보안 그룹에 적용해야합니다. 이 때문에 별다른 이유가 없을 시 awsvpc 모드를 사용하는 것이 좋습니다.실행할 작업의 사용 자원량과 개수에 맞는 인스턴스 유형을 선택합니다. 또한 각 인스턴스 유형에 연결 가능한 최대 네트워크 인터페이스 개수를 확인하고, 최대 네트워크 인터페이스 개수가 인스턴스마다 실행해야할 작업의 개수보다 적다면, 네트워크 인터페이스 trunking이 지원되는 인스턴스 유형을 선택합니다.
생성한 시작 템플릿을 사용하는 오토스케일링 그룹을 생성합니다. 이때 최소 인스턴스 개수와 목표 인스턴스 개수를 0으로 설정하여 빈 오토스케일링 그룹을 만듭니다. 오토스케일링 그룹을 ECS 클러스터 용량공급자로 등록하면, ECS 클러스터가 필요에 따라 목표 인스턴스 개수를 조절할 것이기 때문에 생성 시에는 오토스케일링 그룹이 비어있도록 합니다.
오토스케일링 그룹을 ECS 클러스터 용량공급자로 등록
ECS 콘솔의 방금 생성한 클러스터 메뉴에서 용량공급자 탭의 생성 버튼을 누릅니다. 오토스케일링 그룹으로 방금 생성한 오토스케일링 그룹을 선택합니다. 또한 Managed scaling과 Managed termination protection을 활성화하고, target capacity를 100%로 설정해 오토스케일링 그룹의 모든 인스턴스들을 ECS 클러스터가 관리하도록 합니다.
아직 클러스터에서 실행되어야할 작업이 없으므로, 오토스케일링 그룹에 신규 인스턴스들이 생성되지 않을 수 있습니다. 이제 클러스터에서 실행시킬 작업을 위한 작업 정의를 작성해봅시다.
컨테이너별 Dockerfile 작성
실행할 컨테이너 별로 이미지를 빌드하기 위해 사용할
Dockerfile을 작성합니다. 이 글에서는 하나의 작업에서 애플리케이션 컨테이너와 Nginx 역방향 프록시 컨테이너를 실행하는 상황을 가정하겠습니다. 프로젝트 디렉토리는 다음과 같이 구성합니다.project root
├── taskdef.json
├── buildspec.yml
├── appspec.yml
├── nginx (Nginx 컨테이너)
│ ├── Dokerfile
| └── nginx.conf
└── app (애플리케이션 컨테이너)
├── Dockerfile
├── package.json
└── src
├── main.ts
└── ...Nest.js 애플리케이션의 경우 대략 다음과 같은 형태의
Dockerfile을 작성할 수 있습니다.FROM node:14 AS builder
WORKDIR /app
COPY . .
RUN npm install
RUN npm run build
FROM node:14-alpine
WORKDIR /app
COPY --from=builder /app/dist ./dist
COPY --from=builder /app/node_modules ./node_modules
COPY --from=builder /app/package.json ./package.json
EXPOSE 8081
ENTRYPOINT ["node", "dist/main"]위
Dockerfile에서는 npm을 포함하는 node:14 이미지에서 애플리케이션을 빌드하고, node 런타임 외에는 아무것도 포함하지 않는 node:14-alpine 이미지로 빌드된 애플리케이션을 옮겨 이미지 크기를 최소화합니다.Nginx도 Nginx 이미지에 설정 파일을 수정하도록
Dockerfile을 작성합니다.FROM nginx:stable-alpine
COPY ./nginx.conf /etc/nginx/nginx.conf
EXPOSE 80
ENTRYPOINT ["nginx", "-g", "daemon off;"]Dockerfile을 작성한 뒤에는 항상 docker build 명령어를 통해 로컬 환경에서 빌드가 성공하는지 확인하고, docker run 명령어를 통해 빌드된 이미지가 정상 작동하는지 확인합니다.ECR 이미지 저장소 생성
빌드된 이미지들을 저장할 ECR 이미지 저장소를 생성합니다. ECR 이미지 저장소는 퍼블릿/프라이빗 저장소를 선택할 수 있고, 이미지 태그 변경 가능성을 설정할 수 있습니다. 이미지 태그 변경 가능성이
false로 설정된 경우, 특정 태그의 이미지가 저장소에 이미 존재할 경우 해당 태그의 이미지를 다시 저장소에 푸시할 수 없습니다.CI/CD 파이프라인을 구축하는 경우, 일반적으로 git(또는 다른 VCS)의 커밋 ID의 일부를 이미지 태그로 사용합니다. 가능성은 낮으나, 앞부분이 동일한 커밋 ID가 생성될 가능성이 있으니, 이미지 태그 변경 가능성은
true로 설정합니다. 퍼블릿/프라이빗 여부는 상황에 따라 선택하시면 됩니다. Nginx와 애플리케이션 이미지를 각각 저장해야하므로, 두개의 ECR 이미지 저장소를 생성해주세요.ECR 이미지 저장소를 생성한 뒤, 이미지 저장소 AWS 콘솔에서 View push commands 버튼을 누르면 빌드한 이미지를 ECR 이미지 저장소에 푸시하기 위한 명령어를 확인할 수 있습니다. 각 명령어의 의미를 살펴봅시다.
aws ecr get-login-password --region ap-northeast-2
ECR 레지스트리에 로그인 할 수 있는 비밀번호를 출력합니다. 이 명령어를 실행하기 위해서는 로컬 환경의 AWS CLI에 부여된 자격 증명에
ecr:GetAuthorizationToken 액션 실행 권한이 포함되어 있어야합니다. AWS CLI에 부여될 자격 증명을 관리하는 방법은 AWS 문서를 참조하세요.docker login --username AWS --password-stdin [ECR 레지스트리 URL]
이전 명령어로 발급 받은 비밀번호를 통해 docker CLI가 ECR 레지스트리에 접근 가능하도록 로그인시킵니다.
docker build -t [이미지명] [Dockerfile이 포함된 디렉토리 path]
도커 이미지를 빌드합니다.
docker tag dev-drcha-app:latest [ECR 이미지 저장소 URL]:latest
이전 명령어를 통해 빌드한 이미지가 ECR 이미지 저장소에
latest 태그로 저장될 수 있도록 이미지에 latest 태그를 붙입니다.docker push [ECR 이미지 저장소 URL]:latest
latest 태그를 붙인 이미지를 ECR 이미지 저장소에 푸시합니다.위 명령어들을 통해 Nginx와 애플리케이션 이미지를 빌드하고 각 ECR 이미지 저장소에
latest 태그를 붙여 푸시합니다.taskdef.json 작성
작업 정의 파라미터들을 포함하는
taskdef.json 파일을 작성합니다. 향후 이 파일로부터 AWS 콘솔에서 작업 정의를 생성할 것입니다. CI/CD 파이프라인 구성은 이번 글의 영역이 아니므로 원하는 곳 어디에든 파일을 생성하거나, AWS 콘솔을 사용해 작업 정의를 생성해도 됩니다.{
"family": "sample-application-task-definition",
"networkMode": "awsvpc",
"cpu": "640",
"memory": "1152",
"taskRoleArn": "<TASK_ROLE_ARN>",
"executionRoleArn": "<TASK_EXECUTION_ROLE_ARN>",
"containerDefinitions": [
{
"name": "nginx",
"image": "<NGINX_IMAGE_URL>",
"essential": true,
"cpu": 128,
"memory": 128,
"portMappings": [
{
"protocol": "tcp",
"hostPort": 80,
"containerPort": 80
}
],
"environment": [
{
"name": "[환경 변수명]",
"value": "[환경 변수값]"
}
],
"environmentFiles": [
{
"type": "s3",
"value": "[S3 환경 변수 객체 ARN]"
}
],
"secrets": [
{
"name": "[환경 변수명]",
"valueFrom": "[환경 변수값이 저장된 AWS Secrets Manager secret, 또는 AWS System Manager 파라미터 스토어 파라미터 ARN]"
}
]
},
{
"name": "app",
"image": "<APPLICATION_IMAGE_URL>",
"essential": true,
"cpu": 512,
"memory": 1024,
"portMappings": [],
"environment": [
{
"name": "[환경 변수명]",
"value": "[환경 변수값]"
}
],
"environmentFiles": [
{
"type": "s3",
"value": "[S3 환경 변수 객체 ARN]"
}
],
"secrets": [
{
"name": "[환경 변수명]",
"valueFrom": "[환경 변수값이 저장된 AWS Secrets Manager secret, 또는 AWS System Manager 파라미터 스토어 파라미터 ARN]"
}
]
}
]
}family:taskdef.json파일을 바탕으로 생성될 작업 정의의 패밀리명입니다. 프로젝트명에 맞게 자유롭게 작성하시면 됩니다.
networkMode: 작업의 네트워크 모드. 앞서 설명하였듯, 특별한 이유가 없는 경우awsvpc모드를 사용하는 것이 좋습니다.
cpu,memory: 작업에서 사용할 CPU와 메모리 자원량.cpu의 경우 1024가 1vCPU에 해당하며,memory의 단위는MiB입니다. 작업의 자원량은 작업의 모든 컨테이너에 부여된 자원량의 합보다 커야합니다. 문자열로 입력해야합니다.
taskRoleArn,executionRoleArn: 작업 IAM 역할 ARN과 작업 실행 IAM 역할 ARN입니다. 아직 두 역할을 생성하지 않았으니, 일단은 비워둡니다.
containerDefinitions: 작업에서 실행할 컨테이너 정의 목록.name: 컨테이너명. 이번 글에서는 애플리케이션 컨테이너와 nginx 컨테이너를 한 작업에서 실행하므로,nginx와app으로 설정하였습니다.image: 컨테이너에서 실행할 이미지 URL. 이전 단계에서 빌드해 ECR 이미지 장소에latest태그를 붙여 푸시한 이미지 URL을 입력합니다.essential: 이 필드가true로 설정된 컨테이너 실행에 실패하면 작업 전체가 실행에 실패합니다. 이 필드가false로 설정된 컨테이너 실행에 실패하더라도 작업은 실행에 성공합니다. 한 작업에는 최소한 하나의essential컨테이너가 포함되어야합니다. 이 경우 애플리케이션을 정상적으로 실행하기 위해서는 Nginx와 애플리케이션 컨테이너가 모두 실행되어야하므로 모든 컨테이너를essential컨테이너로 설정합니다.cpu,memory: 컨테이너에서 사용할 CPU와 메모리 자원량입니다. 단위는 작업의 단위와 같습니다. 그러나, 컨테이너의 자원량은 문자열이 아닌 정수로 입력해야합니다.portMapping: 네트워크 인터페이스(hostPort)와 컨테이너(containerPort) 간에 매핑할 포트 목록입니다.awsvpc네트워크 모드의 경우, 네트워크 인터페이스와 컨테이너의 포트를 다르게 설정할 수 없습니다. 또한awsvpc네트워크 모드의 경우, 컨테이너 간 네트워크 연결을 위해 별도의 포트 매핑을 설정할 필요가 없습니다. 작업의 모든 컨테이너에 같은 네트워크 인터페이스가 연결되므로, 로컬 호스트에 포트를 지정해 다른 컨테이너와 네트워크 연결을 만들 수 있습니다. 따라서, 하나의 작업에 포함된 컨테이너들이 모두 다른 포트를 사용해야합니다. 이번 글에서는 Nginx 컨테이너의 80번 포트만 외부로 노출하고, Nginx 컨테이너의 80번 포트로의 요청을 애플리케이션 컨테이너에서 사용하는 포트로 전달하도록 Nginx를 설정합니다.environment: 컨테이너가 실행되는 환경의 환경 변수 목록입니다.taskdef.json파일 또한 깃허브 등에 올라가므로, API key와 같은 민감 정보는 이 필드로 전달하면 안됩니다.environmentFiles: 환경 변수들을 담은 파일을 통해 환경 변수를 설정할 수 있습니다. 현재 지원되는 유일한 파일 유형은 S3 객체입니다.value필드에는 S3 객체의 ARN을 입력합니다.secrets: 민감 정보를 환경 변수로 전달할 때 사용합니다. AWS Secrets Manager의 secert이나, AWS System Manager의 파라미터 스토어 내 파라미터로부터 값을 가져올 수 있습니다.valueFrom필드에 입력할 값은 AWS 문서를 참조하세요.
위 예시에 포함되지 않은 작업 정의의 모든 파라미터에 대한 정의는 AWS 문서에서 확인할 수 있습니다.
작업 IAM 역할 및 작업 실행 IAM 역할 생성
작업 IAM 역할과 작업 실행 IAM 역할 생성에 대해서는 앞에서 설명하였습니다. AWS IAM 콘솔에서 두 역할을 생성합니다. 작업 역할에는 작업이 실행 시점에 가져야할 권한들을 포함한 정책들을 연결합니다.
AWS는 일반적인 작업 실행 역할을 위해
AmazonECSTaskExecutionRolePolicy 관리형 정책을 제공합니다. 하지만 해당 정책은 모든 리소스에 대한 정책이므로 보안적으로 완벽하지 않고, 환경 변수에 대한 권한이 빠져있습니다. 따라서 이번 글에서는 상황에 맞는 작업 실행 역할을 위한 정책들을 직접 생성하도록 하겠습니다. 작업 실행 역할은 크게 세가지 권한이 필요합니다.- ECR 이미지 저장소 접근 및 이미지 다운로드 권한.
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "ecr:GetAuthorizationToken",
"Effect": "Allow",
"Resource": "*"
},
{
"Action": [
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage"
],
"Effect": "Allow",
"Resource": [
"[ECR Nginx이미지 저장소 ARN]",
"[ECR 애플리케이션 이미지 저장소 ARN]"
]
}
]
}- 환경 변수 파일 S3 객체 접근 권한 (
environmentFiles필드를 사용할 경우)
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "s3:GetBucketLocation",
"Effect": "Allow",
"Resource": [
"[환경 변수 파일이 저장된 S3 버킷 ARN]"
]
},
{
"Action": "s3:GetObject",
"Effect": "Allow",
"Resource": [
"[환경 변수 파일 S3 객체 ARN]"
]
}
]
}- 환경 변수로 사용할 민감 정보를 가진 Secrets Manager secret, 또는 System Manager parameter 접근 권한. (
secrets필드를 사용할 경우)
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "secretsmanager:GetSecretValue",
"Effect": "Allow",
"Resource": [
"[Secrets Manager secret ARN]"
]
},
{
"Action": "ssm:GetParameters",
"Effect": "Allow",
"Resource": [
"[System Manager parameter ARN]"
]
}
]
}위 권한들 중 필요한 권한을 포함하는 정책을 생성하여 작업 실행 역할에 연결하세요. 그리고 작업 역할과 작업 실행 역할의 ARN을
taskdef.json에 입력하세요. 더 자세한 작업 실행 IAM 역할 구성 방법은 Amazon ECS 태스크 실행 IAM 역할 문서를 참조하세요.ECS 작업 정의 및 서비스 생성
CodePipeline을 통한 ECS 배포 자동화 파이프라인을 구축하기 전에, 지금까지의 단계들을 바탕으로 직접 ECS 작업 정의와 서비스를 생성하여 직접 애플리케이션을 배포해 봅시다.
작업 정의 생성
먼저
taskdef.json 파일에 작성한 내용을 바탕으로 작업 정의를 생성합니다. AWS ECS 콘솔의 작업 정의 메뉴에서 새 작업 정의 생성 버튼을 통해 작업 정의를 생성합니다. 시작 유형은 EC2를 선택하고, 다음 화면의 맨 아래에서 “JSON으로 설정하기(Configure via JSON)” 버튼을 클릭한 뒤, 위에서 작성한 taskdef.json 파일을 붙여넣고 작업 정의 생성 버튼을 눌러 작업 정의를 생성합니다.서비스 생성 (서비스 기본 설정)
이제 방금 생성한 작업 정의에 대한 작업들을 생성하는 ECS 서비스를 생성합니다. ECS 클러스터 메뉴에서 서비스 탭을 선택하고 생성 버튼을 누릅니다. EC2 시작 유형을 선택하고, 작업 정의는 방금 생성한 작업 정의의 가장 최신 revision을 선택합니다. 서비스명은 자유롭게 작성합니다.
서비스 유형에는 복제(
REPLICA)와 데몬(DAEMON)이 있습니다. 복제는 목표 작업 개수만큼의 작업들을 여러 인스턴스에 분배해 실행하여 방식이고, 데몬은 클러스터에 등록된 모든 인스턴스에 1개씩 작업을 실행하는 방식입니다. 이 글에서는 복제 유형을 선택하고, 목표 작업 개수를 자유롭게 설정합니다.작업 개수는 서비스가 작업 정의로부터 실행 해야할 작업 개수입니다. 실행한 작업 중 일부에 문제가 생겨 작업이 종료된다면, 작업 개수를 맞추기 위해 서비스가 자동으로 필요한 개수의 작업을 실행하게 됩니다.
배포 유형으로 블루/그린 배포를 선택하면, 서비스 생성과 함께 CodeDeploy 애플리케이션과 배포 그룹이 기본 설정값으로 생성되고, CodeDeploy 배포를 통해서만 서비스의 작업 정의를 업데이트할 수 있습니다. 롤링 업데이트를 선택하면 별도의 CodeDeploy 애플리케이션 및 배포 그룹이 생성되지 않습니다. AWS 콘솔에서 서비스의 작업 정의를 변경하면, 롤링 업데이트 방식으로 새로운 작업 정의에 기반한 작업을 배포합니다. 배포 유형은 생성 시 선택한 값을 수정할 수 없습니다.
배포 구성(Deployment Configuration)은 블루/그린 배포 수행 시 요청들을 블루 그룹에서 그린 그룹으로 이전하는 방법들입니다. 1분에 10%씩 이전하는 구성 등, 기본 구성들이 준비되어 있으며, 기본 구성으로 부족한 경우 커스텀 배포 구성을 생성할 수도 있습니다. 롤링 업데이트 배포 유형 선택 시 구성하지 않아도 됩니다. 더 자세한 내용은 CodeDeploy를 사용한 블루/그린 배포 문서를 확인합니다.
CodeDeploy를 위한 IAM 역할은 Amazon ECS CodeDeploy IAM 역할 문서를 참조해 생성하여 연결합니다. 이 역할에 부여된 권한은 이후 단계에서 수정합니다.
작업 배치 전략은 클러스터에 등록된 인스턴스들 중 작업이 실행될 인스턴스를 결정하는 방법입니다. 작업들이 여러 가용 영역에 퍼지도록 구성하거나, 여유 메모리가 가장 많은 인스턴스에 실행되도록 하거나, 두 전략을 모두 사용할 수도 있습니다. 자세한 내용은 Amazon ECS 작업 배치 전략 문서를 확인합니다.
작업 태그 설정은 실행되는 작업에 서비스, 또는 작업 정의에 설정된 태그가 동일하게 설정되도록 할 수 있습니다.
네트워크 설정에서는 작업들이 실행될 VPC와 서브넷, 작업들에 적용될 보안 그룹을 설정합니다. 작업이 실행될 인스턴스가 아닌, 작업에 적용되어야할 보안 그룹 규칙을 여기서 설정하면 됩니다.
서비스 생성 (로드밸런서 설정)
EC2 콘솔에서 서비스에 사용될 로드밸런서를 생성하고, 서비스에 연결합니다. 작업 정의에 포함된 컨테이너와 포트 중, 로드밸런서로부터의 요청이 전달될 컨테이너와 포트를 선택합니다. 이 글의 경우 nginx 컨테이너의 80번 포트를 선택하면 됩니다.
블루/그린 배포 방식을 선택한 경우, 컨테이너와 포트를 선택하면 해당 컨테이너의 포트로 요청을 전달할 리스너와 타겟 그룹 설정 화면이 보여집니다. 롤링 업데이트 방식의 경우 리스너와 타겟 그룹이 자동으로 생성됩니다.
작업들에 전달될 요청을 받을 운영 리스너를 설정합니다. 테스트 리스너는 블루/그린 배포 시 운영 리스너의 요청을 그린 그룹으로 이전하기 전, 그린 그룹에 테스트 요청을 전송해 그린 그룹의 정상 작동 여부를 확인하는데 사용됩니다. 필요하지 않다면 생성하지 않아도 됩니다.
블루/그린 배포 유형을 사용하려면 두개의 타겟 그룹을 생성해야합니다. 블루/그린 배포가 이뤄질때마다, 운영 리스너에 연결되어 있고, 기존 작업들이 등록된 하나의 타겟 그룹이 블루 그룹이 되고, 다른 빈 타겟 그룹이 그린 그룹이 됩니다. 배포가 모두 이뤄지고 나면 블루 타겟 그룹은 비워지고, 그린 타겟 그룹에 새로운 작업들이 생성되고 리스너와 연결되게 됩니다.
서비스 생성 (오토스케일링 설정)
서비스의 목표 작업 개수가 실행 중인 작업들의 CPU 사용량, 메모리 사용량, 또는 작업 별 로드밸런서로부터의 요청 개수에 따라 조정되어야한다면 오토스케일링을 설정합니다. 그렇지 않은 경우 서비스 생성을 마무리합니다.
서비스 생성 완료
길었던 서비스 생성 과정이 끝났습니다! 잠시 기다리면 서비스가 설정된 작업 개수 만큼의 작업을 작업 정의로부터 실행합니다. 실행된 작업은 자동으로 로드밸런서의 타겟 그룹에 등록되어 로드밸런서로부터의 요청을 처리하게 됩니다. 또한 오토스케일링을 설정한 경우, 설정한 지표값이 목표값에서 벗어나면 서비스가 자동으로 작업 개수를 조정하여 지표값을 목표값에 맞추려고 시도합니다.
4. 소소한 팁
이렇게 ECS의 기본 개념들과, ECS 서비스를 통해 작업들을 실행하는 방법에 대해 알아 보았습니다. 글을 마무리하며, ECS 사용 시에 도움이 될 몇가지 팁을 드리고자 합니다.
ECS 모범 사례
ECS AWS 공식 문서는 중요한 개념들과 그렇지 않은 개념들이 섞여 등장해 개인적으로 좋아하지 않지만, ECS 모범 사례 문서는 상당히 좋은 내용들이 포함되어 있습니다. 영문 모범 사례 문서에는 한국어로 아직 번역되지 않아 한국어 모범 사례 문서에 나오지 않는 내용들도 많으므로, 영문 모범 사례를 읽어보시는 것을 추천 드립니다.
대표적인 모범 사례 몇가지는 다음과 같습니다.
- 컨테이너 이미지의 크기를 최대한 작게 유지하라.
- 컨테이너 이미지 하나에서는 하나의 프로세스만 실행하라. 프로세스에 문제가 생겨 정지 되었을 때 이를 재실행하는 것은 컨테이너 내부에서 담당해서는 안되고, ECS가 컨테이너 단위로 관리해야한다.
- 컨테이너 이미지의
latest태그 사용을 지양하고, Git 커밋 ID등을 이미지 태그로 활용하라.
- 애플리케이션이
SIGTERM을 처리하도록 하여 ECS가SIGTERM을 통해 애플리케이션을 종료 시킬 때 데이터베이스 커넥션을 끊는 등 필요한 조치를 취하도록 하라.
블루/그린 배포 시 클러스터 여유 리소스 확보
블루/그린 배포 유형을 선택했다면, 배포 시에 클러스터의 여유 리소스를 확보하시기 바랍니다. 사용자가 서비스의 작업 개수를 늘리거나, 오토스케일링에 의해 서비스 작업 개수가 늘어난 경우, 컨테이너에 추가 작업을 띄우기 위한 리소스(CPU, 메모리, 인스턴스의 유휴 네트워크 인터페이스)가 부족하다면 ECS는 클러스터의 용량공급자로 등록된 EC2 오토스케일링 그룹의 목표 개수를 늘려 추가 리소스를 확보합니다. 그러나, 블루/그린 배포 시에 기존 작업들(블루 그룹)을 유지한 채로 기존 작업 개수만큼의 새로운 작업(그린 그룹)을 실행하는 경우에 클러스터의 여유 리소스가 부족하다면 블루/그린 배포가 완료되지 않고 멈춰 있게 됩니다.
혹시 이 문제의 해결 방법을 아시는 분은 댓글로 알려주시면 감사하겠습니다!
CI/CD 파이프라인
이번 글에서는 다루지 않았지만, 오토피디아에서는 AWS CodePipeline을 통해 CI/CD 파이프라인을 구축해 두었습니다. 대략적인 방법을 설명하자면, Github CodestarConnection을 통해 특정 Github 브랜치에 새로운 푸시가 생긴 경우 소스 코드를 가져옵니다. 이후 CodeBuild가 소스코드에 포함된
buildspec.yml 설정 파일을 기반으로 코드를 빌드하여 ECR 이미지 저장소에 업로드하고, 이미지 URL이 포함된 imageDetail.json 파일을 생성하여 CodeDeploy에 넘깁니다. 그럼 CodeDeploy는 imageDetail.json 파일로부터 이미지 URL을 가져와 소스코드의 appspec.yml 설정 파일을 기반으로 배포를 수행합니다.그러나, 이 방식보다는 Github action을 통해 빌드하시는 방법을 추천 드립니다. CodeBuild는 IAM을 포함한 설정이 복잡한 반면, Github action에는 이미 사용자들이 만들어둔 ECS 배포 액션들이 많아 설정이 훨씬 간편합니다. 무엇보다도, CodeBuild는 느립니다. 서울 리전만의 문제인지는 알 수 없으나, AWS가 제공하는 CodeBuild용 이미지를 사용하더라도 빌드용 인스턴스를 프로비저닝 하는데만 거의 1분이 소요됩니다. Github action은 프로비저닝 시간이 거의 걸리지 않고, 빌드 결과를 캐싱해 둘 수도 있어 빌드 시간이 크게 단축됩니다.
복수의 컨테이너 관리
이번 글에서처럼 한 작업의 복수의 컨테이너가 들어가는 경우, 일반적으로 애플리케이션 컨테이너 한개와, Nginx와 같은 사이드카 컨테이너 여러개가 존재하는 형태가 됩니다. 애플리케이션 컨테이너의 코드가 가장 크고 자주 변경될 것이며, 사이드카 컨테이너들은 보통 설정 파일만을 포함하고 변경 빈도도 아주 낮습니다. 이때 CI/CD 파이프라인을 구축하려면 두가지 문제가 발생합니다.
- Git 커밋 ID를 컨테이너 이미지 태그로 사용해야하는데, 프로젝트 하나에 여러 컨테이너가 포함되므로 컨테이너 이미지 태그 설정 기준이 변경 되어야 합니다.
- 사이드카 컨테이너는 거의 변경되지 않는데, 애플리케이션 컨테이너가 변경될 때마다 사이드카 컨테이너도 빌드 해야 합니다. 빌드 시간이 불필요하게 길어집니다.
이를 해결하기 위해서 저는 다음 방식을 사용했습니다.
- 애플리케이션 컨테이너의 이미지 태그로 Git 커밋 ID를 사용한다.
- 사이드카 컨테이너의 경우 보통 디렉토리내 내용이 설정 파일들 뿐으로 크지 않다. 그러므로 디렉토리 내 모든 파일의 해시값을 컨테이너 이미지 태그로 사용한다.
- 빌드 시에 애플리케이션 컨테이너는 항상 빌드하고, 사이드카 컨테이너의 경우 해시값을 계산한 후, 해당 해시값을 태그로 같는 이미지가 이미 이미지 저장소에 존재하는지 확인한다. 존재한다면 사이드카 컨테이너는 변경 사항이 없는 것이므로 빌드하지 않고, 존재하는 이미지를 사용한다. 존재하지 않는다면 사이드카 컨테이너에 변경 사항이 생긴 것이므로 새로 빌드하여 이미지 저장소에 업로드한다.
이렇게 하면 두 문제를 깔끔하게 해결하면서도, 작업 내 모든 컨테이너 내용을 한 프로젝트에서 관리할 수 있어 아주 편리합니다.
5. 마치며 — 다음엔 같이해요
긴 글을 시간 내어 읽어주셔서 감사합니다.
기술 블로그의 끝은 아시다시피 채용 어필로 이어집니다. ECS를 통해서 더 안정적이고 비용 효율적으로 서비스를 배포 할 수 있는 인프라 환경이 구축 되었는데요. 탄탄한 인프라 위에서 자동차/정비 도메인에 딥다이브하며, 운전자들이 겪는 다양한 차량 문제들을 쉽게 해결해 줄 플랫폼을 함께 만들어 갈 엔지니어 분들을 찾습니다. 공식 채용 페이지를 통해 오토피디아, 일하는 방식, 조직 문화, 채용 중인 포지션에 대해 더 자세한 정보를 확인하실 수 있습니다.
그럼, 다음 글에서 다시 만나요!
글쓴이

.png)
.png)
.png)
.png)