Do not index
안녕하세요, 닥터차의 리서치팀에서 일하고 있는 박기범입니다.
닥터차 서비스를 모르시는 분들을 위해 간단히 소개하면, 닥터차는 20년 이상의 경력을 보유한 자동차 정비 전문 상담사 분들께서 자동차 정비, 수리에 관련한 상담을 무료로 진행해드리는 서비스입니다. 상담사 분들께서는 맞춤형 상담을 통해 이상 진단 및 견적부터 정비소 소개, 부품 구입까지 친절하게 도와드립니다.
저도 이 회사에서 일하기 전부터 닥터차 앱을 썼는데, 차가 있으신 분들께 적극 추천해드리고 싶은 앱입니다.
닥터차의 리서치팀에서는 데이터 수집 파이프라인 구축, 데이터 분석 등을 포함한 데이터 관련 업무를 진행하고 있고, 이외에도 다양한 기술을 적용하여 회사의 업무 효율을 늘리기 위해 노력하고 있습니다.
특히 오늘의 주제인 미응대 상담 알리미는 상담사 분들의 업무 효율을 늘리기 위한 목적으로, 늘어나는 상담에 따른 상담사 분들의 업무 부하로 인해 생기는 미응대 상담에 대응하기 위해 개발되었습니다!
미응대 상담 알리미란?개발 배경개발 과정미응대 상담 알리미 구조데이터 수집답장 중요도 분류 모델 테스트Rule-Based로 중요도 분류하기머신러닝(SVM, Logistic Regression, Decision Tree, Naive Bayes)을 이용한 분류기딥러닝(KoELECTRA)를 이용한 분류기딥러닝 모델 배포미응대 상담 알리미 활용 현황 및 기대효과
미응대 상담 알리미란?
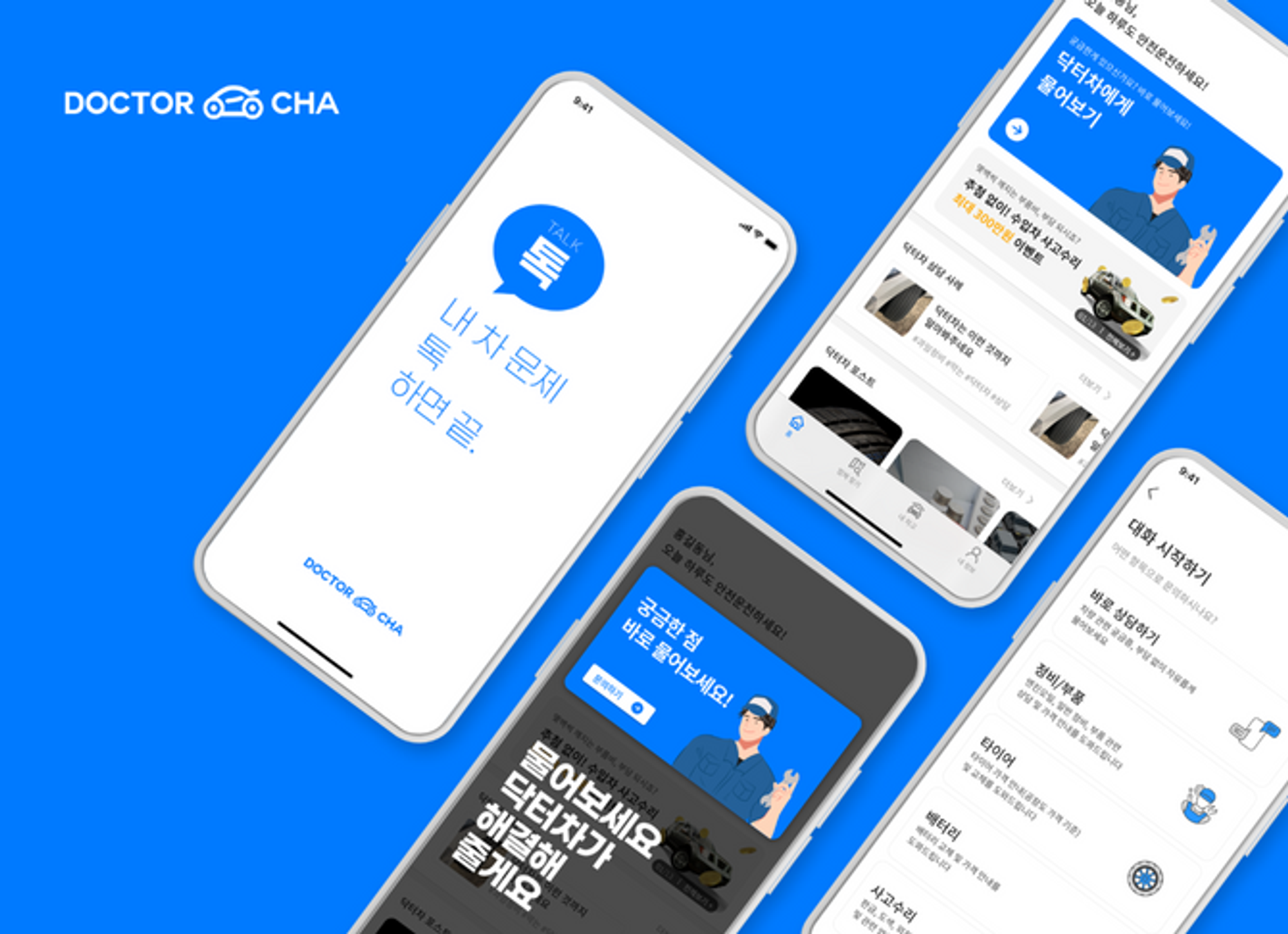
미응대 상담 알리미는 상담을 진행 중에 고객이 보낸 메세지에 상담사 분들이 응답하지 않은 상담을 매일 오후 4시에 슬랙 알림으로 보내주는 시스템입니다.
슬랙 알림에서 마지막으로 상담사가 보낸 메세지와 고객의 메세지를 확인할 수 있고, 해당 상담창으로 바로 이동할 수 있도록 버튼을 만들어 놓았습니다.

위의 사진 2개가 실제 슬랙 알림으로 오는 미응대 상담입니다.
미응대 상담은 크게 두가지로 분류할 수 있는데
- 답장을 반드시 해주어야 하는 중요한 상담
- 상담이 거의 끝나고 종료를 해도되는, 답장의 중요도가 떨어지는 상담입니다.
1번과 같이 답장의 중요도가 높은 상담에는 중요 마크를 붙이고 슬랙 스레드에서 가장 먼저 보일 수 있게 정렬하였습니다.
개발 배경
제가 입사를 한지 한 달이 조금 넘었는데요, 입사 후 상담 분석 업무를 시작하고 나서 미응대 상담 건이 많다는 것을 알게 되었고 매출로 이어질 수 있었지만 답장을 하지 않았던 경우도 많이 있다는 것을 확인하였습니다. 미응대 상담을 줄이는 것이 우리 회사에 시급한 일이라고 생각하여 리서치팀에 제안하였고 미응대 상담 알리미를 만들게 되었습니다.
미응대 상담이 생기는 이유를 알기 위해서는 닥터차에서 이루어지는 상담의 특징에 대해서 먼저 알아야 합니다.
일반적으로 다른 채팅 상담 서비스는 한 고객이 상담을 요청했을 때 상담사 1명이 배정되어 상담을 실시간으로 진행한 후에 곧바로 상담을 종료하기 때문에 상담사가 고객의 메세지에 미응대하는 경우는 거의 없습니다.
하지만 닥터차에서 이루어지는 상담은 고객의 질문에 바로 답변을 줄 수 없는 경우가 많아 짧게는 1일 길게는 일주일 동안 상담이 이루어집니다. 상담 인력이 적기 때문에 상담사 1명이 여러개의 상담을 동시 다발적으로 대응해야 하는 상황입니다.
이러한 이유로 생기는 미응대 상담의 유형과 발생 이유는 다음과 같습니다.
- 반드시 답장을 주어야 하는 고객의 메세지를 확인한 후에 상담사 분들의 바쁜 업무로 답변이 누락되는 미응대 상담.
- 고객이 감사 인사를 보내고 상담이 끝나 종료해도 되는 상담들 중 종료가 되지 않은 상담이 많고 이러한 상담이 미응대 상담으로 분류된다.
미응대 상담 알리미 초기 버전은 고객의 답장에 상담사가 답장하지 않은 모든 상담을 슬랙 알림으로 보내주는 형태였습니다. 하지만 생각보다 너무 많은 미응대 상담이 있어 상담사 분들께서 슬랙에 올라온 미응대 상담을 처리하는데 어려움이 있었고 미응대 상담 중 위의 2번과 같이 상당수가 다시 답장을 주지 않고 상담 종료를 해야하는 경우가 많았습니다.
따라서, 미응대 상담에 대한 중요도를 분류하여 반드시 답장해야하는 상담을 추려내어야겠다는 생각을 했고 이를 위해 딥러닝 모델을 적용하게 되었습니다.
개발 과정
미응대 상담 알리미 구조

오토피디아 데이터 파이프라인에서는 채팅 메세지와 정보가 저장된 서비스 DB의 모든 데이터가 6시간을 주기로 Google BigQuery에 저장됩니다. 따라서 서비스 DB에 직접 접근하지 않고 BigQuery에 저장된 테이블을 통해 쿼리를 작성할 수 있습니다.
- 매일 오후 4시가 되면 Apache Airflow의 DAG 파일에 작성된 코드가 BigQuery의 채팅, 메세지 등에 관련한 여러 테이블을 조인(JOIN)하여 데이터를 가져옵니다.
- 딥러닝 모델에 적용할 수 있는 형태로 후처리를 거친 메세지는 Cloud Run에 도커 컨테이너로 배포해놓은 KoELECTRA 모델에 POST 요청으로 보내지고 KoELECTRA 모델에서 텍스트 분류 과정을 거쳐 각 텍스트의 답장 중요 클래스 예측 결과값을 전달받습니다.
- 이후에는 중요한 답장으로 분류된 채팅을 위주로 정렬하여 슬랙의 웹훅 API를 통해 지정한 슬랙 채널로 보내지게 됩니다.
구조가 복잡하지는 않지만 BigQuery, Cloud Run, Apache Airflow를 잘 모르시는 분을 위해 간단히만 설명 드리자면,
Google BigQuery는 대용량의 데이터를 빠르게 쿼리하여 분석할 수 있는 분석용 데이터 웨어하우스입니다. 많은 스타트업이 데이터 분석을 위해 BigQuery를 사용하고 있습니다.
Cloud Run은 구글의 컨테이너 기반의 서버리스 서비스로, MSA(Microservices Architecture) 를 구현할 수 있습니다.
Apache Airflow는 워크플로우 관리 툴로, 기본적인 Cron Job 부터 Job들간의 의존성 주입, 다양한 오퍼레이터 등을 지원합니다. Airflow는 오픈소스로 온프레미스 또는 클라우드 환경에서 Docker-Compose를 이용해 간단하게 설치, 이용하실 수 있습니다.
데이터 수집
답장 중요도 분류기의 모델을 아직 결정하지 않은 상태에서 데이터 수집을 먼저 진행하였습니다.
처음 수집 단계에서는 모델이 결정되지 않았기 때문에 최대한 간단하고 필요한 양의 데이터를 수집하고, 이 데이터셋으로 모델을 테스트하고 결정된 모델의 특성에 맞게 데이터셋을 고도화하기로 계획하였습니다.
현재 진행중인 상담 중에 아직 상담사가 답변해주지 않은 상담을 모두 모아보니 1000개 정도의 상담을 모을 수 있었습니다. 이때, 상담의 모든 내용을 사용하지는 않고 상담사와 고객이 주고 받은 마지막 턴의 메세지를 모았습니다. 모델을 결정하지는 않았지만 Transformer 기반의 모델을 테스트 할 계획이 있었기 때문에 상담사와 고객의 메세지를 [SEP]로 구분하여 다음과 같이 데이터셋을 정리하였습니다.

모은 데이터셋을 리서치팀 팀원들과 함께 라벨링하였습니다.
- 답변 중요하지 않은 상담 → 0
- 답변 중요한 상담 → 1
이렇게 학습 데이터를 마련하였고, 이를 통해 여러 머신러닝 모델과 딥러닝 모델을 테스트 해볼 수 있었습니다.
여담이지만, 필요 시에는 데이터 구축을 더 고도화하여 진행하려고 했는데 결론적으로 생각보다 모델 성능이 잘 나와서 초기 데이터로 학습한 모델을 사용하였습니다.
답장 중요도 분류 모델 테스트
저희가 하려는 작업은 텍스트 분류(Text Classification) 또는 감성 분석(Sentimental Analysis)라고 볼 수 있습니다. 이미 이를 위한 머신러닝 및 딥러닝 모델은 너무나 많고 좋은 예제 블로그 글을 참고할 수 있었습니다.
특히 저희 리서치팀에는 딥러닝을 너무나 잘 아시는 분들이 있기 때문에 많은 도움을 받을 수 있었습니다.
제가 진행한 리서치 결과와 팀 내부에서의 조언을 바탕으로 다음과 같은 3가지의 테스트를 진행하였습니다.
Rule-Based로 중요도 분류하기
개인적으로는 Rule-Based로 모든 중요도를 분류할 수 있다면 가장 간편하고 좋을 것 같다고 생각했습니다. 하지만 문장 길이, 특정 단어 포함 등의 많은 Rule로 테스트를 해본 결과 너무나 많은 예외 케이스가 존재하여 분류가 쉽지 않았습니다.
머신러닝(SVM, Logistic Regression, Decision Tree, Naive Bayes)을 이용한 분류기
Rule-Based 방식 다음으로 시도해본 것은 전통적인 머신러닝 기법을 이용한 텍스트 분류기 입니다. Scikit-Learn 을 이용하면 몇 분 안에 코드를 짜고 테스트를 돌릴 수 있다는 점과 모델 배포도 pkl 파일로 쉽게 할 수 있어 딥러닝 모델을 사용할 때보다 더 간편하다는 장점이 있다고 생각했습니다.
머신러닝 모델을 학습 시키기 위해서는 텍스트의 인풋을 벡터 형태로 바꾸는 작업을 해주어야 합니다. 이는 Scikit-Learn의 TfidfVectorizer를 사용하여 아주 간단하게 할 수 있습니다.
머신러닝 모델에 알맞게 데이터셋의 인풋을 가공한 뒤에 각각의 머신러닝 모델로 학습한 뒤 성능을 테스트 해보았습니다.

SVM과 Logistic Regression 모델에서 나름 괜찮은 성능이 나오는 것을 확인할 수 있었습니다.

특히 SVM에 대해서는 Recall과 Precision도 확인한 결과 실제로 모델을 배포해도 무방할 정도의 성능을 보여주었습니다.
머신러닝으로는 문맥 정보를 파악하는 것이 힘들기 때문에 성능이 잘 안나올 것이라고 예상했었는데요, 예상했던 것 보다는 훨씬 더 뛰어난 성능을 보여주었습니다.
딥러닝(KoELECTRA)를 이용한 분류기
마지막으로 딥러닝 모델을 테스트 했습니다. 머신러닝도 성능이 괜찮았지만, 딥러닝이라면 더 좋지 않을까라는 기대감이 있었습니다.
모델은 Transformer 계열의 ELECTRA를 한국어 말뭉치에 학습시킨 KoELECTRA를 사용하였습니다.
HuggingFace의 Transformers 라이브러리에 해당 모델이 등록되어있어 아주 쉽게 사용할 수 있고 도큐멘테이션도 잘 정리되어 있기 때문에 Fine-Tuning을 하는데도 별 어려움이 없을 것 같아 해당 모델을 결정하게 되었습니다.
KoELECTRA는 이미 한국어 말뭉치에 대해 학습이 되어있기 때문에 저는 우리가 수행하고자 하는 Task를 더 잘 수행할 수 있도록 Fine-Tuning 공식 가이드를 참고하여 Text Classification을 위한 Fine-Tuning을 진행하였습니다.
처음에는 준비한 데이터셋이 많지 않기 때문에 Fine-Tuning에 시간이 많이 안 걸릴 줄 알고 Mac CPU 환경에서 Fine-Tuning을 했었는데요, 시간이 너무 오래 걸리더라구요..!
그래서 Google Colab을 이용하여 GPU 환경에서 Fine-Tuning을 진행하였고, 4번의 epoch을 도는데 시간은 총 2분 정도 걸렸습니다. Fine-Tuning을 할 때 하이퍼파라미터를 조절해가며 학습을 할 수도 있었지만 일단은 공식 문서와 동일하게 진행을 했고, 성능에 문제가 없다고 판단하여 하이퍼파라미터는 따로 조절하지 않았습니다!

정확도는 89퍼센트 정도가 나와 SVM과 비교했을 때 드라마틱한 개선이 이루어진 것 같지는 않아 살짝 실망을 했었습니다.

하지만 Recall과 Precision을 확인한 결과 Recall(재현율)이 아주 높게 나오고 Precision 또한 나쁘지 않았습니다. 저희는 답장이 중요한 상담을 중요하다고 분류할 수 있는 것이 훨씬 더 중요하기 때문에 평균적인 정확도 보다는 재현율에 더 가중치를 두고 판단하기로 결정했습니다.
따라서, 정확도와 재현율 모두 더 높게 측정된 KoELECTRA 모델을 최종 모델로 채택하였습니다.
딥러닝 모델 배포
일반적으로는 늘어나는 데이터 양에 따라 지속적인 학습이 이루어져야하는 모델이라면 쿠버네티스 기반의 Kubeflow 등을 사용하여 파이프라인을 구축하는 것으로 알고 있습니다.
하지만 미응대 상담 알리미 같은 경우 앱 서비스에 적용되는 딥러닝 모델이 아니고 지속적인 학습이 이루어져야할 필요가 없다고 판단하여 최대한 간단하고 유지보수가 적게 들일 수 있는 도커를 활용한 배포를 진행하였습니다.
처음에는 저희 회사에 구축되어있는 온프레미스 서버에 Docker-Compose로 구성된 Flask+Gunicorn+Nginx 조합의 분류 모델 API Endpoint를 띄워놓고 해당 Endpoint를 Airflow에서 호출하는 방식으로 구성하였습니다만…
왠지 모를 이유로 Airflow에서 같은 로컬 서버에 있는 API Endpoint의 HTTP 요청을 처리하지 못하는 에러가 발생하였습니다. 몇 시간을 투자해서 고치려고 노력해봤지만 쉽게 고쳐지지 않았습니다.

그래서 Cloud Run에 Flask+Gunicorn 조합의 Docker 이미지를 배포하여 Airflow에서 Cloud Run의 Endpoint를 HTTPS 요청하는 방식으로 배포를 진행하였습니다.
아직은 저희 회사의 첫 딥러닝 모델이기 때문에 간단한 방식으로 배포를 진행하였지만 추후에는 더욱 다양한 딥러닝 모델을 개발 및 배포할 예정이기 때문에 Kubeflow, BentoML 등을 사용할 예정입니다.
미응대 상담 알리미 활용 현황 및 기대효과
매일 오후 4시에 미응대 상담 알리미가 슬랙 알림을 보내면 상담사 분들이 해당 내용을 체크하고 중요 마크가 달린 상담을 위주로 미응대 상담을 처리하고 계십니다. 그럼에도 불구하고 밀린 상담 업무가 많아 모든 미응대 상담 건을 처리하지는 못하고 있는 상황입니다.
따라서 저희가 개발한 기술을 적극적으로 사용하실 수 있도록 도와드리고 피드백을 바탕으로 유지보수를 해드리는 것이 이 프로젝트의 마지막 단계이자 가장 중요한 부분이라고 생각합니다.
희망적인 부분은 앞으로 서비스의 규모가 커지고 상담이 많아질 수록 상담사 분들의 수도 더 늘어날 예정이고 그에 따라 미응대 상담 알리미를 전담하는 상담사 분들이 생긴다면 더 큰 효과를 낼 수 있을 것이라고 생각합니다.
앞으로 학습 데이터 보강, 지속적 학습 파이프라인 구축 등의 계획이 더 남아 있는데요 이후에 경험을 또 공유할 수 있도록 하겠습니다. 감사합니다!
글쓴이

.png)
.png)
.png)