Do not index
들어가며아키텍처EKS 사전 탐사EKS Node 선택과정EKS와 TerraformTerraform EKS Module이란?EKS 한 번 만들어봅시다우선 만들어보자EKS IAM기존 테라폼 코드에 끼워넣기재사용 가능한 모듈로 만들자꿀팁. alias 기능 활용하기마치며참고자료
안녕하세요 오토피디아에서 데이터 엔지니어 김건우입니다😀
들어가며
오토피디아에서는 여러 소스에서 발생하고 있는 데이터를 수집하기 위해 초기부터 데이터 파이프라인을 잘 구축해놓았습니다. (이와 관련해서는 케빈이 작성한 오토피디아 데이터 웨어하우스 구축하기 글을 읽어보시는 걸 추천드립니다)
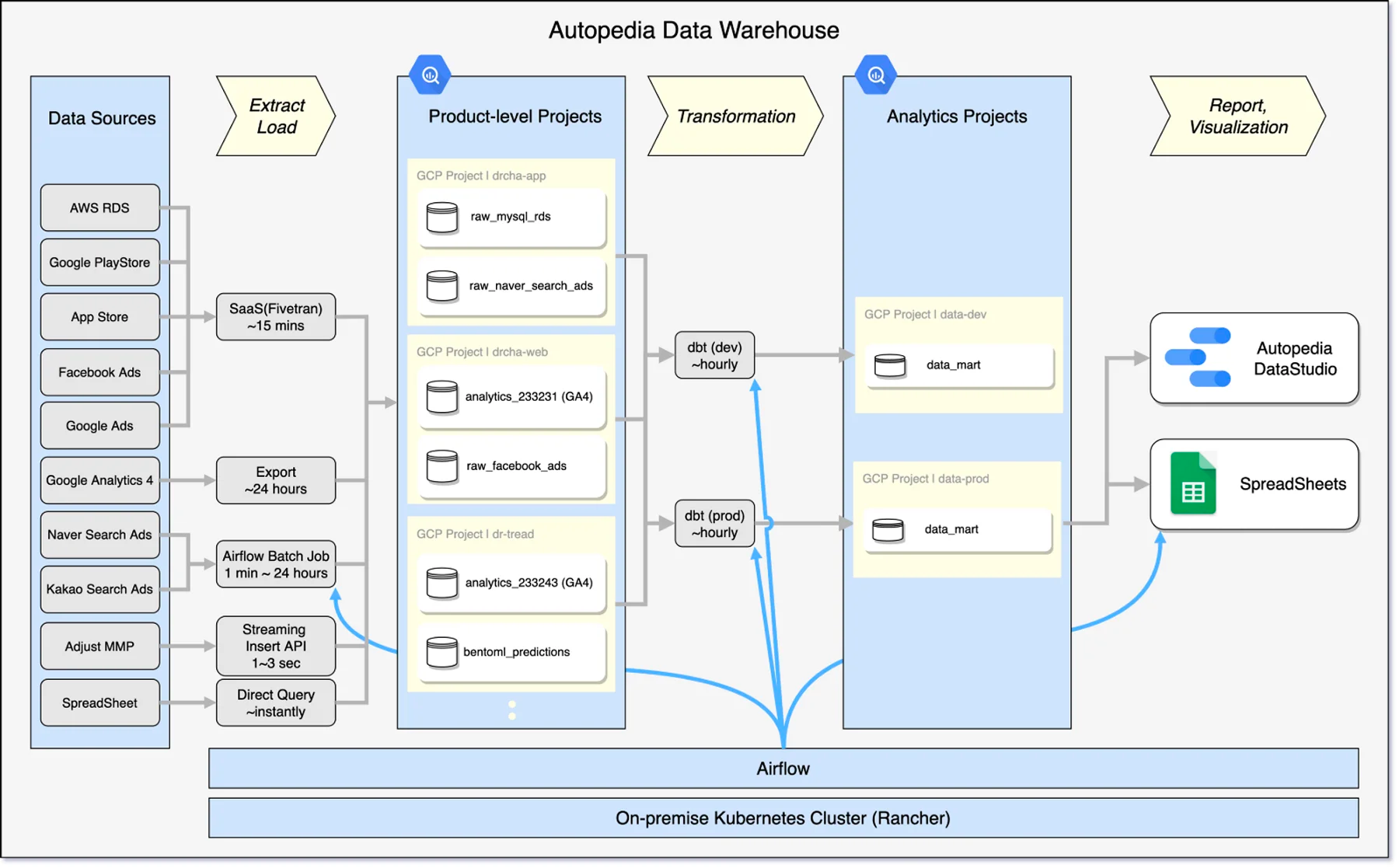
그림에서 보실 수 있다시피 대부분의 파이프라인은 Fivetran, Airflow를 이용한 배치 처리로 수행하고 있었습니다. 하지만 최근 실시간 데이터 처리 플랫폼인 아파치 카프카의 상용 버전 Confluent(이하 컨플루언트)를 사내에 도입하였고, 이에 따라 실시간 파이프라인에 대한 니즈가 생기게 되었습니다.
이번 시간에는 오토피디아에 실시간 데이터 파이프라인 도입 과정과 그 과정에서 제가 했던 삽질들을 공유드리려고 합니다. 특히 많은 삽질 중 이번 글에서는 인프라 구축에 대해 말씀드릴 예정입니다.
아키텍처
.png)
본격적인 구축 과정을 소개드리기 전에 전체 아키텍처를 설명드리려고 합니다. 먼저 원천 소스는 운영 데이터베이스(이하 DB)입니다. DB에 쌓이는 데이터를 카프카를 통해 데이터 웨어하우스(이하 DW)로 사용중인 BigQuery(이하 빅쿼리)에 옮기는 파이프라인을 구성하고자 했습니다.
DB에 쌓이는 데이터는 커넥터를 통해 produce, consume 되도록 하였는데요. 커넥터를 이용하면 별도의 관리없이 간편하게 특정 소스의 데이터를 카프카 토픽에 적재하거나 사용할 수 있습니다. 커넥터는 원활한 운영을 위해 EKS를 이용하여 클러스터에 띄우도록 하였습니다. 또한 개발 환경과 운영 환경 각각에 대해 따로 관리하기 위해 dev, prod 두 개의 클러스터로 만들었습니다.
아마 눈치가 빠르신 분들은 알아채셨을 수도 있는데 클러스터와 DB가 같은 VPC에 위치하고 있습니다. 운영 DB는 기본적으로 퍼블릭 엑세스가 불가능하기 때문에 다른 네트워크에 있다면 VPC 피어링과 같은 방법을 이용하여 통신을 하여야 하지만 가장 간단한 방법으로는 한 VPC에 위치하도록 할 수도 있습니다.
EKS 사전 탐사
실시간 파이프라인 구축을 위해 본격적인 세팅을 시작해봅시다. 가장 먼저 해야할 일은 커넥터를 배포할 클러스터를 만드는 일입니다. 저희는 on-premise로 쿠버네티스를 운영하고 있어 활용가능한 클러스터가 있긴 하였지만 접근성과 확실한 안정성을 위해 앞서 말씀드렸듯이 EKS를 이용하기로 하였습니다.
EKS(Elastic Kubernetes Service)는 AWS의 관리형 쿠버네티스 클러스터 서비스로 직접 온프레미스에 쿠버네티스를 띄우고 관리하지 않아도 AWS 클라우드에서 간편하게 쿠버네티스를 운영할 수 있는 서비스입니다. EKS 외에도 GCP의 GKE, Azure의 AKS 등 다양한 관리형 쿠버네티스가 있습니다. EKS가 더 궁금하신 분들은 AWS에서 제공하는 EKS Workshop을 통해 구조와 사용법을 습득하실 수 있으니 참고하시면 좋을 것 같습니다.
EKS Node 선택과정
쿠버네티스를 사용하려면 기본적으로 클러스터를 구성해야하고, 클러스터를 구성하기 위해서는 여러 개의 노드가 필요합니다. EKS에서는 노드를 구성하는 방법을 3가지 제공합니다.
- EKS on Fargate: 컨테이너 서버리스 서비스로 완전 관리형 노드
- EKS on Managed Node Group: AWS EC2 기반 관리형 노드
- EKS on Self Managed Node Group: AWS EC2 기반 자체 관리형 노드
저희는 클러스터에 대한 관리 비용을 줄이기 위해 Fargate와 관리형 노드 그룹 중 고민을 하였고, 최종적으로는 관리형 노드 그룹을 선택했는데요. 여기에는 2가지 이유가 있었습니다.
- 확장성 측면에서 Fargate가 좋지만 현재 상황에는 확장성이 크게 중요하지 않음
- Fargate는 컨테이너라는 특성상 stateless한 리소스에 적합한데, 이번 EKS에서 운영될 어플리케이션이 stateful한 리소스(Connector, schema registry…)가 많은 상황
- 물론 fargate도 EFS(Elastic File System)를 이용하여 stateful한 리소스를 커버할 수 있지만 추가적인 설정을 해주어야 함
- 비용 측면에서 Fargate보다 저렴한 관리형 노드 그룹
⇒ 가장 범용적이고 관리 비용이 적은 관리형 노드 그룹(EKS on Managed Node Group(이하 MNG))으로 결정!
EKS와 Terraform
자 이제 어떤 종류의 노드를 사용할지도 결정하였으니 클러스터를 띄워야겠죠? 이를 위해서 아주 간단하게는 콘솔을 이용할 수도 있고, AWS CLI를 이용하거나,
kubectl 과 유사한 느낌(?)의 EKS 전용 명령어인 eksctl 를 이용할 수도 있습니다. 하지만 이번에 제가 사용한 방법은 Terraform(이하 테라폼)입니다! 오토피디아에서는 인프라를 Terraform으로 관리하고 있는데요. AWS는 물론 Elastic Cloud, Confluent와 같은 다른 클라우드 서비스들도 모두 테라폼으로 관리하고 있습니다. 테라폼은 코드로 인프라를 관리하는 IaC(Infra as Code)를 위해 HashCorp에서 개발한 오픈소스 클라우드 인프라 프로비저닝 툴입니다. 테라폼을 이용하면 인프라 엔지니어 없이도 코드로 쉽게 인프라를 배포하고 관리할 수 있습니다.
EKS 역시 클라우드 서비스이기 때문에 테라폼을 이용하여 아주 손쉽게 배포를 할 수 있습니다. 특히나 AWS의 거의 모든 서비스는 손쉽게 사용할 수 있도록 테라폼에서 모듈이라고 불리는 형태로 미리 만들어져 있기 때문에 더욱 더 간편하게 배포를 할 수 있습니다. 저 또한 이번 프로젝트에서 모듈을 약간 커스텀하여 쉽게 배포를 할 수 있었습니다.
Terraform EKS Module이란?
앞서 말씀드렸듯이 테라폼에서 제공하는 EKS 모듈을 이용하면 일일이 모든 리소스를 만들 필요없이 간단하게 EKS에 필요한 리소스를 배포할 수 있습니다. 모듈은 마치 메소드와 같아서 변수만 넣어주면 원하는 리소스를 만들 수 있습니다. 아래는 EKS 모듈의 일부입니다.
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 19.0"
cluster_name = "my-cluster"
cluster_version = "1.24"
cluster_endpoint_private_access = true
cluster_endpoint_public_access = true
enable_irsa = true
eks_managed_node_group_defaults = {
disk_size = 50
}
eks_managed_node_groups = {
general = {
desired_size = 1
min_size = 1
max_size = 10
labels = {
role = "general"
}
...
...
}미리 정의되어 있는 EKS source를 불러온 다음 커스텀하길 원하는 변수를 그 안에 적절한 값으로 넣어주기만 하면 됩니다. 위의 모듈에서는 my-cluster라는 클러스터 이름을 가진 쿠버네티스 1.24 버전을 사용한다고 명시했네요. 굉장히 다양한 변수들이 있는데 자세한 내용은 EKS 모듈 공식 문서를 참고하시면 좋을 것 같습니다.
그러면 본격적으로 테라폼으로 EKS를 구축한 과정을 제가 구축했던 의식의 흐름(?)대로 소개해드리겠습니다. 꽤나 많은 과정이 있어서 일부는 생략하였다는 점 양해부탁드립니다.
EKS 한 번 만들어봅시다
구축과정에서 꽤나 많은 삽질들이 있었는데요. 과정을 정리하면 아래와 같습니다.
- 우선 만들어보자
- 기존 테라폼 코드에 끼워넣기
- 재사용 가능한 모듈로 만들자
우선 만들어보자
어떻게 시작할지 막막한 상황에서 어찌됐든 일단 만들어보는 것이 맞겠다는 생각에 테라폼 모듈로 EKS를 먼저 만들어보고자 하였습니다. 제가 띄울 EKS는 기존 테라폼으로 띄웠던 다른 AWS 리소스와는 독립적인 환경이었는데요(이것은 큰 착각이었다…) 그리고 뒤에 카프카를 배포해야 하는 더 어려운 과정도 있었기에 일단은 빠르게 구축하자는 목표가 있었습니다. 그래서 테라폼에서도 별도의 Workspace를 만들어 따로 기존 인프라와는 아예 별개로 작업을 시작했습니다.
가장 먼저 provider를 설정해줍니다. 먼저 기본이 되는 AWS 프로바이더와 함께 추가적으로 kubernetes, kubectl과 helm 프로바이더를 사용하였습니다.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.17"
}
kubectl = {
source = "gavinbunney/kubectl"
version = ">= 1.14.0"
}
helm = {
source = "hashicorp/helm"
version = ">= 2.6.0"
}
kubernetes = {
source = "hashicorp/kubernetes"
version = ">= 2.17.0"
}
}
required_version = ">= 1.2.2"
}프로바이더를 지정했다면 이제 바로 모듈을 만들면 됩니다. 생각보다 간단한 과정에 놀라셨을 것 같은데요(사실 하나 더 남아있긴 합니다) 모듈은 위에서 설명드린 것과 같이 공식문서를 보고 본인이 바라는 상태를 지정해주기만 하면 됩니다. 다시 한 번 살펴볼까요?
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 19.0"
cluster_name = "dev-eks"
cluster_version = "1.24"
cluster_endpoint_private_access = true
cluster_endpoint_public_access = true
enable_irsa = true
eks_managed_node_group_defaults = {
disk_size = 50
}
eks_managed_node_groups = {
general = {
desired_size = 2
min_size = 1
max_size = 10
labels = {
role = "general"
}
...
...저희는 노드 종류를 MNG로 결정했는데 이는 모듈 안에
eks_managed_node_groups 이라는 input으로 지정할 수 있습니다. 그리고 해당 input에서 다양한 type을 통해 input의 상태를 지정할 수 있습니다. 위에서는 MNG 노드에 최소 1개에서 최대 10개의 노드까지 생성될 수 있도록 하였고, 기본 상태는 2개 만들었네요.이처럼 모듈은 본인이 바라는 EKS 상태를 선언하기만 하면 아주 손쉽게 리소스를 배포할 수 있습니다. 그러면 바로 배포를 해볼까요? 먼저
terraform init 으로 초기화를 해주고 바로 terraform apply로 배포를 할 수 있습니다. 참고로 apply를 하기 전에 terraform plan 명령어를 통해 미리 제대로 코드를 작성했는지 점검해볼 수도 있습니다.terraform init
terraform applyEKS 배포는 적게는 5분 많게는 15분 정도 정도 시간이 걸리는데요. 인고의 시간을 기다리면 우리가 원하는 상태로 EKS가 배포되는 것을 확인할 수 있습니다.

EKS IAM
자 그러면 이제 모든 배포가 끝났습니다!..라고 말하고 싶지만 아직 할 게 더 남아있습니다. 콘솔을 확인해보면 아마 이런 경고창이 떠있을텐데요.

해당 경고창이 뜨는 이유는 configmap aws-auth에 현재 사용자 또는 역할이 등록되어 있지 않기 때문입니다. 이를 이해하기 위해서는 EKS IAM 개념을 알아야 합니다.
기본적으로 EKS 접근은 kube-system 네임스페이스 내에 위치한
aws-auth 컨피그맵을 통해 관리됩니다. 클러스터를 만든 사용자는 컨피그맵을 수정할 수 있는 권한이 주어지는데요. 클러스터에 접근하기 위해서는 컨피그맵을 수정하여 적절한 권한을 부여해야 합니다.여기에는 두 가지 방법이 있습니다.
- configmap에 직접 유저를 추가
- Role(역할)을 만들고 유저에게 부여
첫번째 방법은 가장 간단한데요. 그냥 클러스터에 접근할 유저들을 일일이 넣어주는 방식입니다. 클러스터에 접근할 유저가 적고, 앞으로 추가/변경될 일이 없다면 나쁘지 않지만 관리를 하기에 썩 좋은 방법은 아닙니다.
두번째 방법은 제가 채택한 가장 효율적인 IAM 관리법입니다. 그 전에 AWS에서 역할(Role)의 역할(?)은 무엇일까요? 역할은 기본적으로 Policy(권한)을 갖는다는 점에서 사용자와 비슷합니다. 만약 역할이 없다면 우리는 일일이 사용자에게 적절한 권한을 부여해야 합니다. 이러한 귀찮음을 방지하기 위해 역할에 적절한 권한을 부여하고 사용자는 해당 역할은 획득하여 권한을 얻게 됩니다. 이를 임시 보안 자격 증명이라고 합니다.
두번째 방법을 이용하기 위해서는 아래와 같이 IAM을 생성해야 합니다.
- EKS에 대한 적절한 권한을 가지고 있는 Policy 생성 (aws_iam_policy)
- 해당 권한을 가진 Role 생성 (aws_iam_role)
- Policy와 Role 연결 (aws_iam_role_policy_attachment)
IAM을 다 생성했다면 EKS에 접근할 준비가 끝난건데요. 로컬에서
kubectl 명령을 이용하고 싶다면 몇 가지 설정이 더 필요합니다. 로컬에 ~/.aws config 파일을 설정해주는 일인데요. 순서는 아래와 같습니다.aws configure --profile <user_name>로 configure에 사용자 profile 등록
- user가 생성한 Role을 부여받을 수 있도록 Role 이름으로
~/.aws/config에 새로운 profile을 생성
[profile <role_name>]
role_arn = arn:aws:iam::<arn_id>:role/<role_name>
source_profile = <user_name>aws eks update-kubeconfig --name <eks_name> --region <리전명> --profile <생성한 profile_name>로~/.kube/config에 업데이트
마지막으로 이제 EKS 모듈의
aws-auth 에 사용자와 역할을 등록해야 합니다. 이는 EKS 모듈의 aws_auth_roles와 aws_auth_users input을 사용하면 됩니다.aws_auth_roles = [
{
rolearn = aws_iam_role.eks_admin.arn
username = aws_iam_role.eks_admin.name
groups = ["system:masters"]
},
]
aws_auth_users = local.eks_admins위의 코드를 보고 약간 이상함을 느끼신 분들이 있을 것 같은데요.
aws_auth_users 가 지역변수로 처리되어 있다는 것입니다. 해당 지역변수는 EKS에 접근할 수 있는 사내 사용자들이 리스트로 이루어져 있습니다. 아마 귀찮음을 참지 못하는 개발자 분들은 그냥 IAM 그룹으로 처리하면 되는거 아냐?라고 생각하셨을 것 같습니다. 하지만 안타깝게도 EKS에서는 IAM 그룹을 지원하고 있지 않고 있기 때문에 어쩔 수 없이 사용자들을 일일이 넣어주어야 하는데요(일해라 AWS🥲)
저는 코드 상에 사용자들을 관리하는 것은 맞지 않다고 생각했고, 결론적으로는 Terraform Cloud에서 사용자 리스트를 변수로 만든 뒤 지역변수를 활용하여
aws_auth_users 에 적절한 값으로 생성하여 사용하였습니다.덕분에 사용자를 코드 상에서 관리하지 않고 필요할 때마다 테라폼 클라우드에서 사용자를 추가하거나 삭제할 수 있게끔 만들었습니다.
이렇게 IAM 생성까지 완료했다면 처음에 봤던 에러없이 정상적으로 EKS에 접속할 수 있게 됩니다.
기존 테라폼 코드에 끼워넣기
사실 원래는 이렇게 EKS 구축을 끝내고 카프카까지 구축을 마무리한 상태였습니다. 하지만 몇 가지 문제가 있었는데요.
- EKS와 DB의 종속성 문제
- EKS 내에 카프카 커넥터가 DB의 binlog를 읽을 수 있어야 했기에 필히 같은 VPC에 위치해야 했음. 하지만 둘은 서로 다른 repo에 있었기에 vpc id를 코드에 직접 주입해주야 했는데 이는 보안이나 관리 측면에서 좋지 못했음.
- 비효율적인 인프라 코드 관리
- 모든 AWS 관련 인프라를 하나의 repo에서 관리하는 상황이었기에 EKS만 따로 관리를 하는 것이 비효율적이었음.
- 또 다른 EKS 클러스터 구축 니즈
- 카프카를 위한 EKS 외에도 이 후 머신러닝 학습을 위한 EKS가 또 필요할 수도 있었기에 재사용성이 낮은 현재의 형태는 적절하지 못함
위의 문제들로 인해 모듈을 처음부터 뜯어고쳐야만 했는데요. 가장 먼저 할 일은 기존 테라폼 코드에 EKS 모듈을 끼워넣는 작업이었습니다. 저희는 AWS 뿐 아니라 다양한 인프라를 하나의 repo에서 관리하고 있는 상황이었고 이를 구분하기 위해 인프라마다 폴더를 만들어 모듈로 만들어 사용하고 있었습니다.
그렇기 때문에 EKS를 만들기 위해서는 aws 폴더에 안에 구축한 EKS 모듈을 만들어야 했고, 위에서 만든 방식 그대로 모듈을 먼저 구축하였습니다. 앞서 구조를 미리 만들어놓았기 때문에 기존 코드에 EKS 모듈을 다시 끼워넣는 과정은 그렇게 어렵지 않았습니다.
기존 인프라 코드에 끼워넣음으로써 aws output을 사용하기가 한층 수월해졌고, vpc id나 subnet id를 직접 변수로 관리하지 않아도 출력값으로 사용이 가능하게 되었습니다. 또한 반대로 DB에도 해당 클러스터가 접근할 수 있도록 보안그룹을 열어주어야 하는데요. 이는
aws_security_group_rule 리소스를 통해 설정할 수 있습니다.참고로 apply를 통해 인프라를 재구축할 때 잘못하면 클러스터가 만들어지지도 않았는데 DB가 보안그룹을 만들려고 하여 에러가 발생하는 불상사가 발생할 수도 있습니다. 이는
depends_on 을 이용하여 리소스 간에 종속성을 만들어 방지할 수 있습니다.resource "aws_security_group_rule" "allow_kafka_tasks_default_db_cluster_mysql_ingress" {
security_group_id = aws_security_group.default_db_cluster.id
type = "ingress"
...
depends_on = [
module.eks_kafka
]
}재사용 가능한 모듈로 만들자
기존 인프라 코드에 EKS 모듈을 끼워넣는 과정은 그리 어렵지 않았습니다. 조금 더 까다로웠던 부분은 재사용 가능한 EKS 모듈을 만드는 것이었습니다. 재사용 가능한 모듈을 만들려면 클러스터 이름, 인스턴스 타입, 디스크 사이즈 등 사용자가 클러스터 설정값을 직접 세팅할 수 있도록 변수화 해야 했습니다.
이를 위해 모듈 안에 값들은 모두 변수 처리하였고 이를 모듈 밖에서 직접 지정할 수 있도록 하였습니다.
# eks 모듈
module "eks" {
source = "terraform-aws-modules/eks/aws"
cluster_name = local.prefix
cluster_version = "1.24"
eks_managed_node_group_defaults = {
disk_size = var.disk_size
}
eks_managed_node_groups = {
default = {
desired_size = var.desired_size
min_size = var.min_size
max_size = var.max_size
...
}
}
...
}# 파생 모듈
module "eks_derivative" {
source = "./modules/eks"
environment = var.environment
cluster_name = "derivative"
disk_size = 20
min_size = 2
max_size = 3
...
}이렇게 함으로써 클러스터를 만들고 싶다면 새로운 파일을 생성하고 원하는 상태값을 지정하기만 하면 되도록 구조를 재구축하였습니다. 이번 카프카 클러스터는 아래와 같은 구조를 가지고 있습니다. eks 모듈을 eks-kafka에서 이용하여 클러스터를 만들었고, 만약 머신러닝용 eks를 만들고 싶다면 eks-ml이라는 파일을 새로 만들어서 변수를 지정하고
apply 를 해주면 됩니다..
├── README.md
├── aws
│ ├── default-database.tf
│ ├── eks-kafka.tf
│ ├── modules
│ │ ├── eks
│ │ │ ├── eks.tf
│ │ │ ├── iam.tf
│ │ │ ├── main.tf
│ │ │ ├── outputs.tf
│ │ │ └── variables.tf
│ ├── versions.tf
...꿀팁. alias 기능 활용하기
EKS 구축은 모두 끝이 났는데 마무리 전에 테라폼에
alias 기능을 소개해드리려고 합니다. 위에서는 언급하지 않았지만 테라폼이 쿠버네티스 API를 사용할 수 있게 하려면 kubernetes 프로바이더에 클러스터에 대한 토큰값을 넘겨주어야 합니다. (자세한 내용은 테라폼 kubernetes provider 문서를 참고해주세요)이 때 문제는 쿠버네티스 프로바이더에는 하나의 클러스터 값만 넘겨줄 수 있다는 것입니다. 이렇게 되면 테라폼이 여러 개의 EKS 클러스터를 이용할 수 없겠죠. 이를 해결하기 위해 테라폼의 alias를 활용할 수 있습니다.
alias는 말 그대로 프로바이더에 대한 별명을 지정할 수 있는 기능인데요. 클러스터의 alias를 만들고 이를
configuration_aliases 에 넘겨주면 테라폼이 여러 개의 쿠버네티스를 이용할 수 있게 됩니다. 사용 예시는 아래와 같습니다.provider "kubernetes" {
host = cluster_1_endpoint
cluster_ca_certificate = base64decode(cluster_1.certificate_authority[0].data)
...
alias = "cluster_1"
}
provider "kubernetes" {
host = cluster_2_endpoint
cluster_ca_certificate = base64decode(cluster_2.certificate_authority[0].data)
...
alias = "cluster_2"
}
terraform {
required_providers {
}
kubernetes = {
source = "hashicorp/kubernetes"
version = ">= 2.17.0"
configuration_aliases = [kubernetes.cluster_1, kubernetes.cluster_2]
}
}
...
}마치며
이렇게 카프카 커넥터를 위한 EKS 클러스터 구축이 마무리 되었습니다. 아무래도 EKS에 익숙하지 않고 특히 IAM 설정에서 이해가 어려운 부분이 많아서 쉽지 않은 작업이었는데요. 단순히 인프라를 구성하는데 그치지 않고 재사용성, 보안 등 다양한 부분들을 챙기면서 더욱 더 배우는 것이 많았던 것 같습니다.
긴 글 읽어주셔서 감사하고 다음에 더 알찬 글로 찾아뵙겠습니다!
참고자료
글쓴이



.png)
.png)
.png)